21 KiB
学习js数据结构与算法 & 算法图解
栈
十进制转二进制
除2取余,直到整数为0,反向输出余数。
function divideBy2(num) {
var stack = [],
result = '';
while(num > 0) {
stack.push(Math.floor(num % 2));
num = Math.floor(num / 2);
}
while(stack.length) {
result += stack.pop().toString();
}
return result;
}
十进制转任意进制
function baseConverter(decNumber, base) {
var stack = [],
digits = '0123456789ABCDEF',
result = '';
while(decNumber > 0) {
stack.push(Math.floor(decNumber % base));
decNumber = Math.floor(decNumber / base);
}
while(stack.length) {
result += digits[stack.pop()];
}
return result;
}
队列
循环队列
链表
- 单链表
- 双向链表
- 循环链表
集合
- 并集
- 交集
- 差集
- 子集
字典和散列表(HashMap)
散列表
选择散列函数
一个表现良好的散列函数是由几个方面构成的:插入和检索元素的时间(即性能),当然也包括较低的冲突可能性。
也有一些为数字键值准备的散列函数,你可以在找到一
系列的实现。
处理散列值冲突
处理冲突有几种方法:分离链接、线性探查和双散列法。
-
分离链接法 包括为散列表的每一个位置创建一个链表并将元素存储在里面。
-
线性探查 当想向表中某个位置加入一个新元素的时候,如果索引 为index的位置已经被占据了,就尝试index+1的位置。如果index+1的位置也被占据了,就尝试 index+2的位置,以此类推。
在一些编程语言中,我们需要定义数组的大小。如果使用线性探查的话,需
要注意的一个问题是数组的可用位置可能会被用完。在JavaScript中,我们不需
要担心这个问题,因为我们不需要定义数组的大小,它可以根据需要自动改变大
小——这是JavaScript内置的一个功能。
- 双散列法 即在同义词产生地址冲突时计算另一个散列函数地址,直到冲突不再发生,这种方法不易产生“聚集”,但增加了计算时间。
树
基本术语
结点: 包含一个数据元素及若干指向子树的指针。
结点的度(Degree): 结点拥有的子树数。
叶子(Leaf)(终端)结点: 度为零的结点。
分支(非终端)结点: 度大于零的结点。
树的度: 树内各结点度的最大值。
孩子(Child): 结点的子树的根称为该结点的孩子。
双亲(Parent): 该结点称为孩子的双亲。
兄弟(Sibling): 同一双亲的孩子之间互称为兄弟。
祖先: 从根到该结点所经分支上的所有结点。
子孙: 以某结点为根的子树中的任一结点都称为该点的子孙。
层次: 从根开始定义,根为第一层,根的孩子为第二层,以此类推。
堂兄弟: 双亲在同一层的结点互为堂兄弟。
深度(Depth): 树中结点的最大层次称为树的深度或高度。
有序树 & 无序树: 如果将树中结点的各子树看成从左至右是有序的,则称该树为有序树,否则为无序树。
森林(Forest): m(m>=0)棵互不相交的树的集合。
二叉树(BinaryTree): 每个结点至多只有两棵子树且左右有序。
二叉搜索树(BST): 左边存储比父节点小,右边存储比父节点大的二叉树。
树的创建(BST)
function BST() {
function Node(value) {
this.value = value;
this.left = null;
this.right = null;
this.parent = null;
}
this.root = null;
this.addNode = function(value) {
var node = new Node(value);
if (this.root == null) {
this.root = node;
} else {
var currentNode = this.root;
var isContinue = true;
while(isContinue) {
if (value < currentNode.value) {
if (currentNode.left) {
currentNode = currentNode.left;
} else {
currentNode.left = node;
isContinue = false;
}
} else if (value > currentNode.value) {
if (currentNode.right) {
currentNode = currentNode.right;
} else {
currentNode.right = node;
isContinue = false;
}
}
}
}
}
}
// 递归写法
function insertNode(root, newNode) {
if (root === null) {
root = newNode;
} else {
if (newNode.value < root.value) {
if (root.left === null) {
root.left = newNode;
} else {
insertNode(root.left, newNode);
}
} else {
if (root.right === null) {
root.right = newNode;
} else {
insertNode(root.right, newNode);
}
}
}
}
树的遍历
中序遍历(左根右)
// 递归写法
function traveseTree(node, callback) {
if (node !== null) {
traveseTree(node.left, callback);
callback(node);
traveseTree(node.right, callback);
}
}
// 非递归写法(借助栈)
function traveseTree(root, callback) {
var stack = [];
var p = root;
if (root == null)
return;
while(stack.length || p) {
// 第一步:遍历左子树,根节点入栈(为了后面根据根节点找到右子树)
while(p) {
stack.push(p);
p = p.left;
}
// 第二步:出栈(p指向栈顶元素,取p的右子树重复以上过程,直到栈为空且p为空)
callback(p = stack.pop());
p = p.right;
}
}
先序遍历(根左右)
// 递归写法
function traveseTree(root, callback) {
if (root != null) {
callback(root);
traveseTree(root.left);
traveseTree(root.right);
}
}
// 非递归写法(借助栈)
function traveseTree(root, callback) {
var p = root,
stack = [];
if (root == null) return;
while(stack.length || p) {
// 第一步:先遍历左子树,边遍历边打印,并将根节点存入栈中,以后借助跟节点进入右子树开启新一轮遍历
while(p) {
callback(p);
stack.push(p);
p = p.left;
}
p = stack.pop();
p = p.right;
}
}
后序遍历(左右根)
// 递归写法
function traveseTree(root, callback) {
if (root != null) {
traveseTree(root.left);
traveseTree(root.right);
callback(root);
}
}
// 非递归写法(借助栈)
// 后序遍历的难点在于:需要判断上次访问的节点是位于左子树,还是右子树。若是位于左子树,则需跳过根节点,先进入右子树,再回头访问根节点;若是位于右子树,则直接访问根节点。
function traveseTree(root, callback) {
var pCur = root, pLast = null, stack = [];
if (root == null) return;
// 先把pCur移到左子树最下边
while(pCur) {
stack.push(pCur);
pCur = pCur.left;
}
while(stack.length) {
pCur = stack.pop();
//一个根节点被访问的前提是:无右子树或右子树已被访问过
if (pCur.right == null || pCur.right == pLast) {
callback(pCur);
pLast = pCur;
}
/*这里的else语句可换成带条件的else if:
else if (pCur->lchild == pLastVisit)//若左子树刚被访问过,则需先进入右子树(根节点需再次入栈)
因为:上面的条件没通过就一定是下面的条件满足。仔细想想!
*/
else {
// 根节点再次入栈
stack.push(pCur);
// 进入右子树,且可肯定右子树一定不为空
pCur = pCur.right;
while(pCur) {
stack.push(pCur);
pCur = pCur.left;
}
}
}
}
层次遍历(利用队列实现)
- 根节点入队
- 出队
- 如果有左孩子,左孩子入队;如果有右孩子,右孩子入队。
- 重复步骤2、3,直到队列为空。
function traveseTree(root, callback) {
var queue = [];
if (root == null) return null;
queue.push(root);
while(queue.length) {
var frontNode = queue.shift();
callback(frontNode);
if (frontNode.left) queue.push(frontNode.left);
if (frontNode.right) queue.push(frontNode.right);
}
}
树的查找
- 最小值:左子树最下边
- 最大值:右子树最下边
- 特定值:先序遍历
树的删除
// 删除值为value的节点
function removeNode(node, value) {
if (node == null) return null;
if (value < node.value) {
node.left = removeNode(node.left, value);
return node;
} else if (value > node.value) {
node.right = removeNode(node.right, value);
return node;
} else {
//情况1:节点为叶节点(有零个子节点的节点)
if(node.left == null && node.right == null) {
node = null;
return node;
}
//情况2:只有一个子节点的节点
if (node.left == null) {
node = node.right;
return node;
} else if(node.right == null) {
node = node.left;
return node;
}
//情况3:有两个子节点的节点
// 先找到右边子树节点的最小值节点
// 再用最小值节点的值更新当前节点的值
// 最后删除右边子树最小值节点
var findMinNode = function(node) {
if (node) {
while(node && node.left !== null) {
node = node.left;
}
return node;
}
return null;
}
var aux = findMinNode(node.right);
node.value = aux.value;
node.right = removeNode(node.right, aux.value);
return node;
}
}
其他扩展
- 红黑树
- AVL平衡二叉搜索树
图
图的表示
- 邻接矩阵:顶点用数组索引表示,
a[i][j] = 1来表示边。缺点是浪费一些空间。 - 邻接表:每个顶点的相邻顶点列表组成。
- 关联矩阵:行表示顶点,列表示边,
a[i][j] = 1表示边j的入射顶点为i。
function Graph() {
this.vertices = [];
this.vertexMap = new Map();
this.adjList = new Map();
this.addVertex = function(v) {
return this.vertexMap.has(v.id) ? null : (v.status = 0, this.vertexMap.set(v.id, v), this.vertices.push(v),this.adjList.set(v.id, new Set()), v);
};
this.addEdge = function(sourceId, targetId) {
if (this.vertexMap.has(sourceId) && this.vertexMap.has(targetId)) {
this.adjList.get(sourceId).add(this.vertexMap.get(targetId));
this.adjList.get(targetId).add(this.vertexMap.get(sourceId));
}
return this;
};
this.getVertex = function(id) {
return this.vertexMap.get(id);
};
this.getVertexAdj = function(id) {
return this.adjList.get(id) || [];
};
this.toString = function() {
this.adjList.forEach((value, key) => {
console.log(key + ':' + Array.from(value).map(e => e.id).join(',') + '\n');
});
};
}
图的遍历
- 广度优先(BFS):用队列实现。
- 深度优先(DFS):用栈实现。
用 status 表示节点状态:
- 0 - 初始状态
- 1 - 被探索状态
- 2 - 被访问过状态
// 广度优先(BFS)算法:用**队列**实现。
/*
1. 创建一个队列 Q
2. 将 v 标记为 1,并入队
3. 如果 Q 非空,重复以下步骤
3.1 将 u 出队
3.2 寻找 u 的相邻节点,并将未被访问的节点入栈,并标记为 1
3.3 访问节点,标记为 2
*/
function BFS(root, callback) {
var queue = [];
if (root == null) return null;
root.status = 1 && queue.push(root);
while(queue.length) {
var curVertex = queue.shift();
// 将相邻节点入队
var adjVertexs = graph.getVertexAdj(curVertex.id);
adjVertexs.forEach(e => {
// 忽略已经入队或已经被访问过的节点
if (e.status === 0) {
e.status = 1 && queue.push(e);
}
});
// 节点被访问
callback(curVertex);
curVertex.status = 2;
}
}
// 深度优先(DFS)算法:用**栈**实现。
function DFS(graph, callback) {
var stack = [];
var vertexs = graph.vertices;
// 遍历每个节点,若节点未被访问,则入栈
// 若栈非空,出栈
// 继续遍历其相邻未被访问的子节点
for (var i = 0, length = vertexs.length; i < length; i++) {
if (vertexs[i].status === 0) {
vertexs[i].status = 1;
stack.push(vertexs[i]);
while(stack.length) {
var v = stack.pop();
v.status = 2;
callback(v);
var adjVertexs = graph.getVertexAdj(v.id);
adjVertexs.forEach(e => {
if (e.status === 0) {
e.status = 1;
stack.push(e);
}
});
}
}
}
}
// 递归写法
function DFS(v, callback) {
if (v == null) return;
callback(v);
v.status = 2;
var adjVertexs = graph.getVertexAdj(v.id);
adjVertexs.forEach(e => {
if (e.status === 0) DFS(e, callback);
});
}
排序和搜索算法
冒泡排序
两两比较,一轮比较后最大的数沉到底部。
两层循环:
- 外层循环表示比较的轮次
- 内层循环表示每一轮冒泡
function bubbleSort(arr) {
for (var i = 0, len = arr.length; i < len; i++) {
// 改进: j < len - 1 - i,已经排好序的可以不用再比较
for(var j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) {
swap(arr, j, j+1);
}
}
}
}
选择排序
找到最小值,放到第一位;找到第二小的值,放到第二位,依次类推......。
function selectionSort(arr) {
var minIndex;
for (var i = 0; i < arr.length-1; i++) {
minIndex = i;
for (var j = i+1; j < arr.length; j++) {
if (arr[j] < arr[minIndex]) {
minIndex = j;
}
}
swap(arr, minIndex, i);
}
}
插入排序
往已经排好序的数组里面插入待排序的元素。
假设数组第一项排好序,从第二项开始,与前面的比较,如果比前面小,继续向前,直到比前面的大。
function insertionSort(arr) {
if (arr.length < 2) return arr;
for (var i = 1, len = arr.length; i < len; i++) {
var j = i - 1;
var temp = arr[i]; // 相当于将i提取出,留个空位
while(j >=0 && arr[j] > temp) {
arr[j+1] = arr[j];
j--;
}
arr[j+1] = temp;
}
}
归并排序
归并排序是一种分治算法。其思想是将原始数组切分成较小的数组,直到每个小数组只有一 个位置,接着将小数组归并成较大的数组,直到最后只有一个排序完毕的大数组。
// https://www.cnblogs.com/chengxiao/p/6194356.html
function mergeSort(arr) {
var len = arr.length;
if (len === 1) return arr;
var mid = Math.floor(len/2);
var left = arr.slice(0, mid);
var right = arr.slice(mid, len);
return merge(mergeSort(left), mergeSort(right));
}
function merge(left, right) {
var i = 0,
j = 0,
l = left.length,
r = right.length,
temp = [];
while(i < l && j < r) {
if (left[i] < right[j]) {
temp.push(left[i]);
i++;
} else {
temp.push(right[j]);
j++;
}
}
if (i < l) {
temp.push(...left.slice(i));
}
if (j < r) {
temp.push(...right.slice(j));
}
return temp;
}
快速排序
分治算法。一次排序分两半,一半小,一半大,直到左指针大于右指针。
(1) 首先,从数组中选择中间一项作为主元。 (2) 创建两个指针,左边一个指向数组第一个项,右边一个指向数组最后一个项。移动左指 针直到我们找到一个比主元大的元素,接着,移动右指针直到找到一个比主元小的元素,然后交 换它们,重复这个过程,直到左指针超过了右指针。这个过程将使得比主元小的值都排在主元之前,而比主元大的值都排在主元之后。这一步叫作划分操作。 (3) 接着,算法对划分后的小数组(较主元小的值组成的子数组,以及较主元大的值组成的子数组)重复之前的两个步骤,直至数组已完全排序。
function quickSort(arr, left, right) {
var index;
if (arr.length > 1) {
index = partition(arr, left, right);
if (left < index - 1) {
quickSort(arr, left, index-1);
}
if (right > index) {
quickSort(arr, index, right);
}
}
}
function partition(arr, left, right) {
var pivot = arr[Math.floor((left+right)/2)],
i = left,
j = right;
while(i <= j) {
while(arr[i] < pivot) {
i++;
}
while(arr[j] > pivot) {
j--;
}
if (i <= j) {
swap(arr, i, j);
i++;
j--;
}
}
return i;
}
// 《算法图解》思路
// 基线条件:空数组或长度为1的数组不需要排序
// 递归条件:每次选择一个基准值,得到三个部分(小于基准值 + 基准值 + 大于基准值)
// 对基准值两边的数组继续快排,并将最后的数组合并
function quickSort(arr) {
if (arr.length < 2) return arr; // 基线条件
var baseIndex = Math.floor(arr.length / 2); // 基准值
var leftArr = [];
var rightArr = [];
for (var i = 0, len = arr.length; i < len; i++) {
if (i !== baseIndex) {
if (arr[i] < arr[baseIndex]) {
leftArr.push(arr[i]); // 小于基准值部分
} else {
rightArr.push(arr[i]); // 大于基准值部分
}
}
}
// 最后合并
return quickSort(leftArr).concat([arr[baseIndex]]).concat(quickSort(rightArr));
}
顺序搜索
一一对比。
二分搜索(二分查找)
对于已排好序的数组。
function binarySearch(arr, value) {
var left = 0,
right = arr.length - 1;
var mid;
while(left <= right) {
mid = Math.floor((left+right)/2);
if (value < arr[mid]) {
right = mid - 1;
} else if(value > arr[mid]){
left = mid + 1;
} else {
return mid;
}
}
return -1;
}
算法补充知识
递归
尾调用是指某个函数的最后一步是调用另一个函数。
// 递归
function fibonacci(num) {
if (num === 1 || num === 2) return 1;
return fibonacci(num-1) + fibonacci(num-2);
}
// 非递归
function fibonacci(num) {
var n1 = 1, n2 = 1, n=1;
for (var i = 3; i <= num; i++) {
n = n1 + n2;
n1 = n2;
n2 = n;
}
return n;
}
动态规划(Dynamic Programming, DP)
是一种将复杂问题分解成更小的子问题来解决的优化技术。
要注意动态规划和分而治之(归并排序和快速排序算法中用到的那种)是不同的方法。 分而治之方法是把问题分解成相互独立的子问题,然后组合它们的答案,而动态规划则是将问题分解成相互依赖的子问题。
解决的问题:
-
背包问题:给出一组项目,各自有值和容量,目标是找出总值最大的项目的集合。这个 问题的限制是,总容量必须小于等于“背包”的容量。
-
最长公共子序列:找出一组序列的最长公共子序列(可由另一序列删除元素但不改变余 下元素的顺序而得到)。
-
矩阵链相乘:给出一系列矩阵,目标是找到这些矩阵相乘的最高效办法(计算次数尽可 能少)。相乘操作不会进行,解决方案是找到这些矩阵各自相乘的顺序。
-
硬币找零:给出面额为d1…dn的一定数量的硬币和要找零的钱数,找出有多少种找零的 方法。
-
图的全源最短路径:对所有顶点对(u, v),找出从顶点u到顶点v的最短路
贪心算法
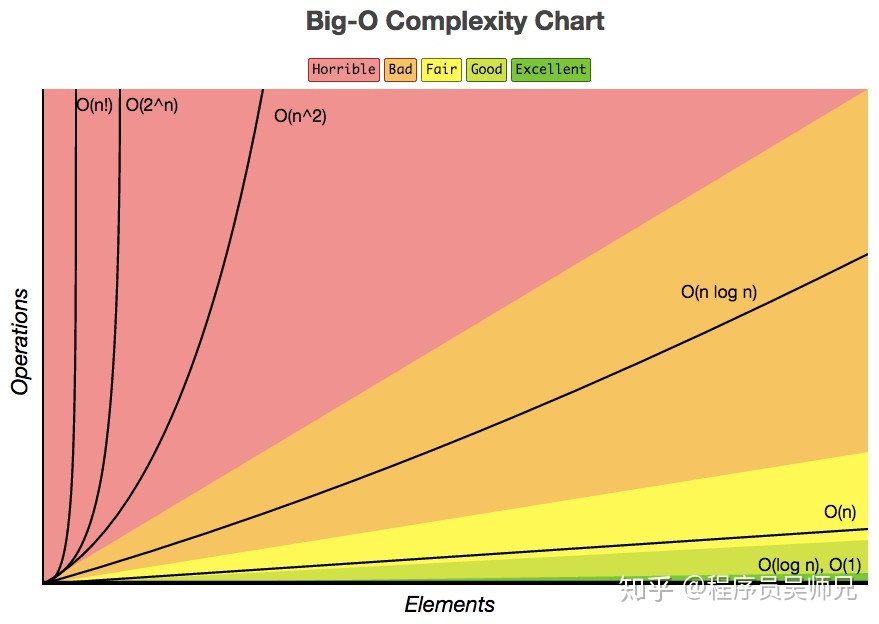
大 O 表示法
时间复杂度速查表